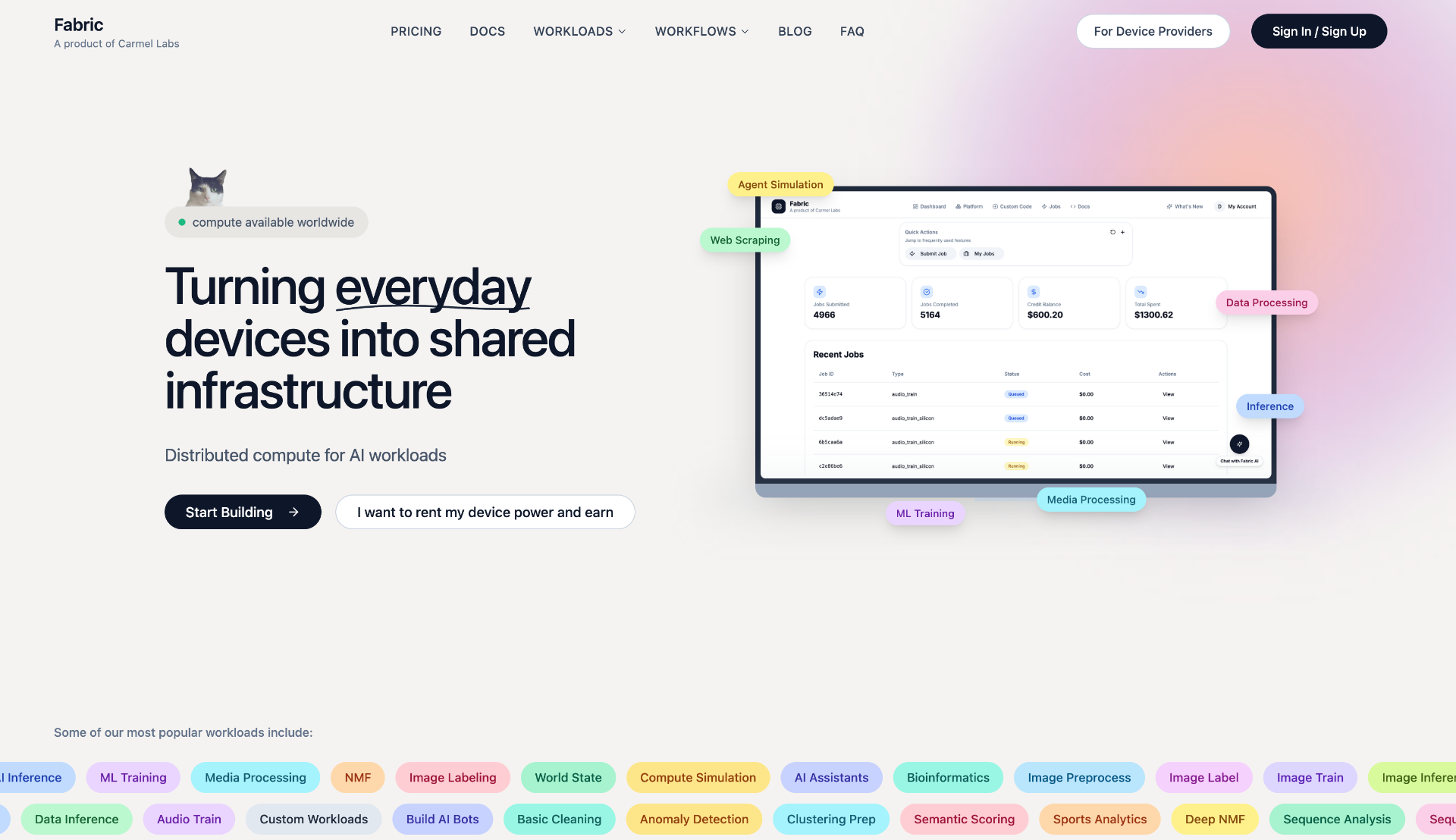
Fabric is a distributed compute platform for AI workloads that connects idle compute power worldwide. It enables users to run inference jobs at a fraction of traditional cloud costs while allowing device owners to earn passive income.
Fabric by Carmel Labs is a distributed AI compute platform that converts idle computing power from devices worldwide into a passive income opportunity. It caters to two distinct user groups: device owners who want to monetize their unused CPU and GPU cycles, and AI practitioners who need cost-effective inference compute. The platform's core value proposition is eliminating wasted compute while enabling earnings for individuals anywhere. With over 800 devices already joined and $10,500+ paid out, Fabric demonstrates real traction in the distributed compute marketplace. The process begins with a lightweight agent that runs in the background, requiring minimal intervention from the user.
Traditional cloud-based AI inference can be prohibitively expensive, especially for researchers, startups, or hobbyists needing sporadic compute. At the same time, millions of personal computers sit idle for hours each day, their processing power unused. Fabric solves this inefficiency by creating a secure bridge between compute supply and demand. Device owners earn passive income from resources that would otherwise remain idle, while AI job runners gain access to distributed computing at a fraction of typical cloud pricing. This peer-to-peer model reduces costs and democratizes access to AI compute. The platform addresses common user concerns about safety through sandboxed execution, zero data collection, and end-to-end encryption, ensuring device owners can participate without worry.
The first major feature group focuses on safety and control. All jobs run inside locked sandboxes with no access to personal files, browsing history, or any private data. The physical separation ensures that even if a job is malicious, it cannot reach the user's documents or photos. Additionally, Fabric implements end-to-end encryption for all network traffic, preventing interception of job data or communications. Device owners retain complete control over resource allocation through adjustable CPU and memory limits. The platform never collects personal data, and users can pause participation at any time with a single click. These safety measures are non-negotiable, as emphasized on the Fabric website: "Your safety is not negotiable."
A second feature set revolves around earnings transparency and ease of use. The dashboard displays every completed job, its exact payout, and a cumulative earnings statement without hidden fees. Users can see "Today's Earnings" and "This month" summaries in real time. Payouts occur weekly with no minimum threshold, meaning even small earnings are accessible immediately. The lightweight agent automatically pauses when the device needs full computing power for user tasks, ensuring that sharing resources never impacts performance. Users set their own schedule and can stop earning at any moment. The simplicity of the interface is captured in the tagline: "It's almost too simple." This transparency builds trust and encourages continued participation.
Publisher
A
admin
Launch Date2026-02-13
Platformweb
Pricingpaid
Domain Authority
Ahrefs DR11/100